
Consent
Consent is the way that parties agree to participate in a proposed activity, event, or arrangement. In the context of research, consent is a particularly important topic as it respects the autonomy of the data subject to voluntarily engage in the research process. If we breakdown the word consent, it is comprised of the following root terms: con (together) + sentire (feel) = Feel together, a mutual feeling (Peña and Varon 2019, 24). Thus, the etymology of the word consent speaks to the idea of mutuality of feeling. There are legal requirements for consent, which are outlined in more detail in the Current Data Protection Guidelines section. Here, the aim is to move beyond legalities and examine the social context or contract that informs the notion of consent. This broader understanding of consent is especially important when it comes to both the original collection of data online as well as the reuse or secondary uses of data.
Click to Consent
We are all familiar with checking boxes and clicking buttons as a way to consent to our data being collected by social media and commercial websites in exchange for access to their services and platforms. The Edward Snowden files and the Cambridge Analytica scandal revealed the negative political, social, and economic impacts of this practice and how little we understand what our data is, its value to others, and how it can be used against us for political marketing.
Although there are far more protections around medical scan data than data we provide to social media platforms, it is important to keep in mind broader discussions around the problematics of “consent” in the digital age and ask whether they can steer creative researchers towards considering consent issues more sensitively and mindfully as artists working with personal data. In their 2019 publication “Consent to Our Data Bodies: Lessons from Feminist Theories to Enforce Data Protection,” Paz Peña and Joana Varon bring a feminist lens to thinking through consent to data usage. They remind us that consent is at the heart of social movements against sexual abuse and harassment movements such as #MeToo, and that its meaning, when discussing justice as it relates to the violation of the physical (typically female) body, is contested or avoided. They explain the problematics of binary consent options and the illusion that consent can be a free, rational, and individual choice. When a simple click can give access to a website, or, in the case of some medical research projects, to a potentially life-saving study, is there really a choice? In the same way that terms and conditions for social media sites are unreadable, is there a risk that research ethics information sheets and consent forms (and, dare we say, artist statements and project proposals) are equally unintelligible, prompting us to click through rather than meticulously scroll through the entire text?
In his paper “Biometric Privacy Harms,” American legal scholar Matthew Kugler (2019) points to a series of studies showing that people’s opinions about the use of biometric data are far from binary. Rather than just opting in or out from data-sensitive technologies, people want more nuanced, granular, and informed choices. Kugler cites a study by Research Now/SSI (which has since become Dynata) that found that most people were comfortable using their thumbprint to unlock a smartphone or banking app but much less comfortable with allowing department stores to use facial recognition software to send them targeted ads. Studies also showed that younger people generally have “greater privacy expectations” than older people. Kugler and Peña and Varon all point to evidence that people are not generally willing to pay for more privacy, and that the more choices offered by organizations using biometric identity systems, the better. These studies show that it is necessary to review and reassess boundaries and expectations around privacy.
Incidental Findings
When medical scan data is acquired for research, there is a requirement that scans are reviewed for incidental findings by a medical doctor. Any incidental findings are confidential and only shared with the data subject and their physician (if this is requested in the consent form by the data subject). At this stage, the data subject may decide to withdraw their consent for their data to be used in the study.
The nature of artistic practice is that artworks evolve and shift as they are developed, making consent withdrawal or ongoing consent a best practice when seeking permission to use personal data in the production of an artwork. Ideally, the person who has given permission for their data to be used is given the opportunity to see the artwork as it is being made and before it is exhibited publicly so they understand how their data is being presented and contextualized. There may be instances where subjects are uncomfortable with how their data is being represented or if something is revealed, much like an incidental finding. When making the VR artwork My Data Body, which uses the artist Marilène Oliver’s Facebook data, Oliver discovered that Facebook stores all searches that have ever been made by the user. Oliver was uncomfortable with including her Facebook search terms in the work, so this data was deleted from the project.
A framework that could be adopted to protect all parties when an incidental finding is discovered in personal data while creating an artwork is one used in contracts for artist commissions where the artist provides preliminary sketches and final sketches to the client that both parties agree upon at agreed dates in the project. CARFAC Ontario provides examples of contracts for private and public commissions via their website for a small fee (CARFAC Ontario 2016).This process would protect both the artist (who is investing considerable amount of time and resources in the creation of the artwork) and the person giving permission to use their data (who can’t fully understand the impact of the artwork until they see/experience it).
Longitudinal studies
Longitudinal studies are a very useful methodological approach to collecting large amounts of data about specific populations. Cohort studies are a subset of longitudinal studies that follow a group of people of a specific age range, often beginning with children and following them through a significant portion of their life. Such examples include two British cohort studies, the 1958 National Child Development Study (Power and Elliott 2006), an ongoing study which involves 17,415 people born in 1958 in England, Scotland, and Wales, and the Millennium Cohort Study (Joshi and Fitzsimons 2016), which is following 19,000 people in England, Scotland, Wales, and Northern Ireland who were born between 2000 and 2002. In these cases, it would have been the parents who consented to the child’s participation, which means the participants themselves are not the ones granting consent. This scenario could lead to issues as children become adults and have the ability to understand the implications of participation and are able to withdraw now but not retroactively (Helgesson 2005).
In her essay on the HUMAN Project (Human Understanding through Measurement and Analytics), American anthropology professor Shannon Mattern (2018) explains how the longitudinal project aims to “measure everything we possibly can about 10,000 people over the course of the next 20 years or more.” It aggregates multiple data (location, activity, health, sleep, gaming, banking, voting) about the individuals in the study and cross-references it with environmental, social, and political conditions (Mattern 2018). This study will undoubtedly yield unexpected results as technology and social factors change that could impact participants’ levels of comfort with the study. Ethically, such longitudinal studies would benefit from ongoing informed consent, as participants’ understanding of and consent to participation could change over the course of the study (Helgesson, Ludvigsson, and Stolt 2005).
Machine learning “troubles” consent
Likewise, the need to understand and be transparent about the systems into which data is being fed and processed is essential. Peña and Varon (2019) remind us that asking for “informed” consent is an oxymoron when machine learning is applied to data. Machine learning relies on unsupervised algorithms to find patterns and rules within a dataset in order to perform a given task (generate new images, text, scan data, social media posts). It is impossible to know what the algorithm is learning from the dataset (Bridle 2018). How can researchers ensure informed consent when they don’t know what the algorithm is learning from data? This problem is even more important when large, aggregated datasets are used, as it is very difficult to fully inspect and understand the contents of the dataset. The opacity of machine learning algorithms does not mean that artists shouldn’t work with machine learning, but if machine learning is used to process a person’s data in a creative or artistic project, how the machine learning was developed and how it will be used should be clearly explained to them. It is also important to be aware of the many massively funded machine learning projects currently working to realize data aggregation in the future. Banking, for example, is an industry that is investing heavily in biometrics as way to tackle identity fraud. If (or when) biometric markers such as fingerprints and retinal scans become the “keys” to our data, there is a risk that aggregated data could be used in ways we presently cannot predict.
Healthier qualifiers of consent
Research ethics procedures for human data collection already require that information and consent is communicated to participants in clear and plain language that meets the informational needs of the individual. There is an opportunity here to think about consent more broadly as an ongoing process that takes into account better boundaries that empower the participants to understand their data and involve them in the direction of the project. If participants can be involved because data has been anonymized, are there ways to understand the conditions under which permission was obtained, and can this become part of the content of the work? In their conclusion, Peña and Varon (2019) propose a set of “healthier qualifiers for consent” that are helpful when working with personal data. Although not all of them are practical (or necessary), they can be actively considered and aspired to as a way to arrive at a “mutual feeling” for each other’s data bodies. They state, the act of consent needs to bena) active, meaning actively agreeing with body and words to do so (not only the absence of no); b) clear and intelligible; c) informed, fully conscious; d) freely given, out of choice and free will; e) specific to a situation, therefore f) retractable and g) ongoing… (Peña and Varon 2019, 24).
Artists making artworks about the concept of data consent
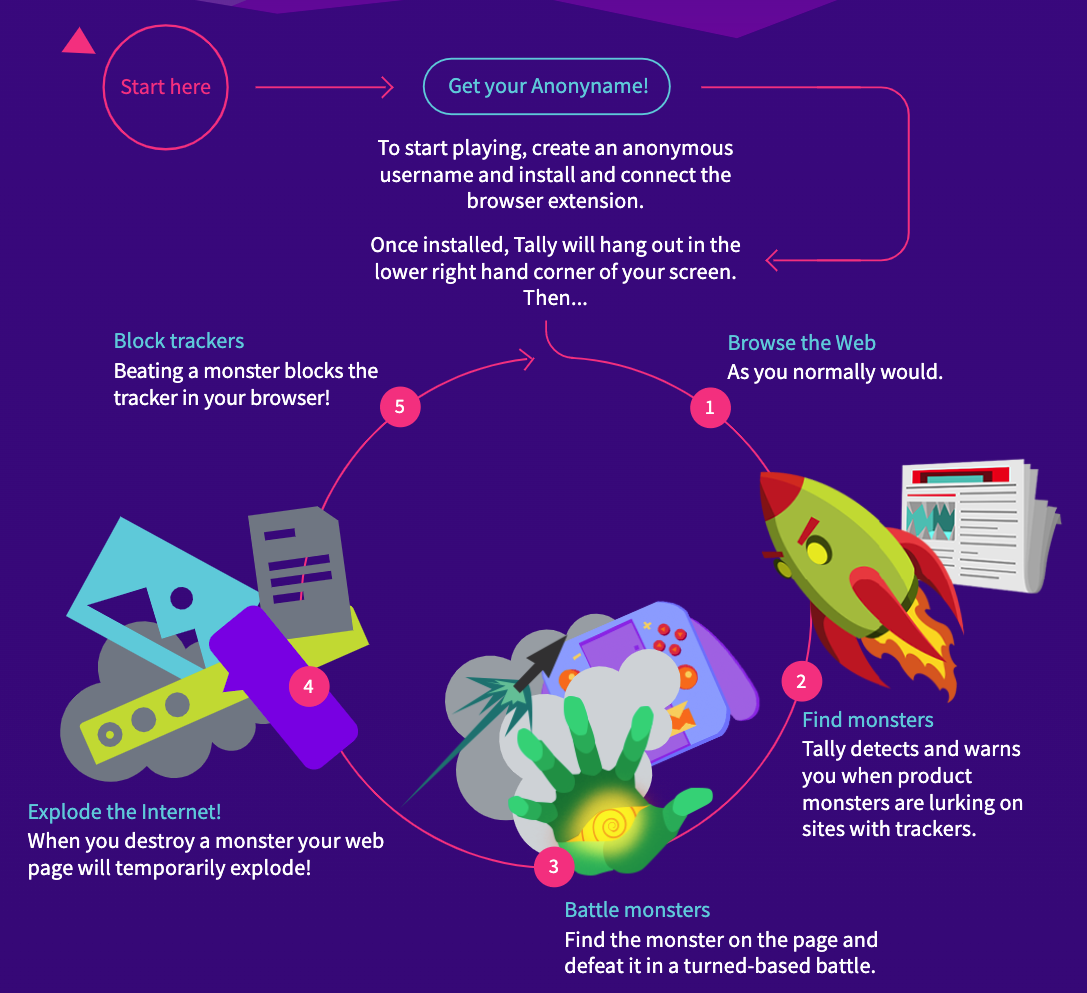
Owen Mundy and Joelle Dietrick (Sneakaway Studio), diagram of Tally Saves the Internet 2021.
Image courtesy of the artist.
Tally Saves the Internet and I Know Where Your Cat Lives are two artworks that playfully reveal how much data we unknowingly “consent” to giving away when we upload images and use the internet. I Know Where Your Cat Lives is a website that allows you to search for cats anywhere in the world via Google Maps. To create the work, Owen Mundy and his team used seven million public images of cats and plotted them using the metadata in the uploaded images (Mundy and Berger, n.d.)The project is both playful and sinister; we are both pulled in by the cute photos of cats and repelled by how our beloved, domestic felines are so precisely geolocated by Google. The project website explains clearly how the project was created and advises you to increase the privacy settings of your images to avoid the metadata of your images being unknowingly exploited. Here Mundy demonstrates that whenever we upload an image to a platform such as Flickr, Twitpic, and Instagram we are “consenting” to its metadata also being uploaded and used by the platforms. Another more recent project by Owen Mundy and Joelle Dietrick called Tally Saves the Internet is a game that blocks data trackers and “educates players about data privacy” (Mundy and Dietrick 2020). Tally is a little colourful blob that “hangs out” in the corner of your browser and tells you when advertisers/monsters are collecting data and allows you to battle/block them, “exploding” the internet as you go. In this project, which was conceived with their daughter in mind, Mundy and Dietrick meet many of Peña and Varon’s criteria for obtaining consent. Tally makes consenting to data tracking active, clear, informed, specific to particular webpages, retractable, and ongoing. Choosing to not consent to trackers does not mean exclusion from accessing a webpage.

Marilène Oliver’s scorecard from Stealing Ur Feelings film by Noah Levenson, 2019.
Image courtesy of the artist.
STEALING UR FEELINGS, an interactive film by Noah Levenson made in 2019, uses facial recognition and emotion recognition software to “extract data from your face” as you watch the six-minute documentary about Snapchat’s “Determining a mood for a group” patent (Levenson 2019). As you watch the documentary, includes images of pizzas, cute dogs, and Kanye West, your camera-enabled device watches you. At the end of the documentary, you are offered a downloadable scorecard with the assumptions that AI made about you when you were watching the film, including IQ, annual income, gender and racial bias and how much you like pizza, dogs, and Kayne West. Like Tally Saves the Internet, Levenson’s project offers a way towards “withdrawing” consent by signing a petition against the patent. To access the petition, you have to smile.
In her durational performance LAUREN, artist Lauren McCarthy becomes “a human intelligent smart home” (McCarthy 2017). The performance starts with McCarthy visiting the homes of participants in person (who sign up via the Get-Lauren website) to install a series of networked devices such as cameras, sensors, lights, and door locks. LAUREN then watches over participants 24/7 using the installed cameras and sensors. LAUREN has the ability to remotely control the home of the participant with networked switches. Like the automated and networked assistants Alexa and Siri, LAUREN can be directed by the participants via voice command. LAUREN and will also try to anticipate her participants’ needs and desires as she watches over them and learns their routines. In a video documentary reflecting on the experience of having LAUREN in their homes, participants reported mostly positive reactions. They likened LAUREN to a friendship that is “about them,” and that noted that it feels as though LAUREN is “in support, not in control of them.” (McCarthy 2017). With LAUREN, McCarthy offered participants (and herself) an opportunity to “feel with” surveillance technology in a durational and active way. As McCarthy reflected, the tasks she performed for her participants were mostly those they could easily do themselves, such as flipping switches, playing music, and looking up answers to questions online (McCarthy 2018). . The artist and others may wonder if such menial tasks are worth the requirement that participants provide access to their personal data. Or perhaps there is something else gained from these surveillance technologies, such as a sense of companionship and care? McCarthy writes,
In LAUREN, I am wrestling for control with artificial intelligence. The participants are also negotiating boundaries and poking at the system. The point of this project is not to impose a point of view, but to give viewers a space to form their own. Immersed in the system in the comfort of their homes, people are able to engage with the tensions. Some moments are awkward and confusing, others are hopeful and intimate. Together, we have a conversation. Do we feel any limits when it comes to letting AI into our data, our decision making, and our most private spaces? (2018)
Consent Discussion Questions
• What kind of consent was obtained from the data subjects at the time of collection? Is the consent form available? What kinds of uses were described in the consent form? Does the proposed work conflict with those uses?
• Where was the consent obtained? Where will the data be used in creative work? What are the differences between the laws under which the consent was obtained and the laws under which the dataset is being used? Did the data subjects consent to use of their data outside of their political/legal region? Are there any geographical restrictions within the terms of use of the dataset?
• If acquiring new data, how clear is the explanation of your project and how flexible is the consent form? Are there binary choices (such as opt in or opt out) or are participants given a range of choices in their responses?
• How practical is it to obtain ongoing consent? Should the participant be asked for consent to their data used in every exhibition in which the resulting work will be shown; or should they consent to inclusion of their data in every paper or other form of dissemination?
• What would happen if consent was retracted by the data subject? What would happen in an artist had spent months making an artwork and then the data subject retracted their consent to use their data?
Examples of consent forms
University of Alberta (Open Access) Human Research Ethics Forms and Templates
University of Michigan Informed Consent Guidelines and Templates
https://research-compliance.umich.edu/informed-consent-guidelines