
Provenance, Access, and Licencing
There are many different ways of accessing scan data, whether it be our own existing or newly acquired data, or a dataset that is freely downloadable from the internet (please see the list of selected repositories below).
The question of data ownership in the context of medical scan data (and other kinds of personal data), however, is complex. Data subjects are typically asked to consent to their data being used for research purposes when data is acquired, effectively transferring “ownership” of the data to the researcher. Even if consent is not given at the time of collection, medical data does not necessarily “belong” to the data subject; rather, it belongs to the researchers who, or institution which, acquired the data.
It is likely that it will be impossible for a researcher to contact the original data subject because it has been anonymized or de-identified. It is, however, possible for creative researchers or artists to contact the ethics board of the institution to ask for permission to use the data for artistic purposes, if it is not freely available for research. Even if the data is freely available, there is no harm contacting the original researcher to confirm they are comfortable with an experimental creative research use of the data. Indeed, this can be a way of creating connections or establishing fruitful relationships with other researchers that can lead to future collaborations.
Even when permissions are granted and access to and use of data may therefore be legal, the datasets themselves should also be considered from an ethical standpoint. Who is the subject of the dataset? How were they recruited for participation? Where were the participants located and what were the laws governing their privacy and consent at the time of data collection? What are the differences in privacy and consent regulations in the time and place that the data is being reused? It is not the artist’s responsibility to correct the ethical mistakes involved in the creation of a dataset. Indeed, as we discussed in the last chapter through the work of artists Adam Harvey and Zach Blas, the presence of ethical issues in a dataset may be integral to the work itself.
Working with your own data or the data of close relatives
Depending on where you live in the world and whether you are part of a public or private health care system, getting access to your own medical data is more or less complicated. The GDPR, under Article 15, gives individuals the right to request a copy of any of their personal data. Likewise, Canadian law stipulates that individuals are entitled to request a copy of their own data. The process of actually getting a copy of scan data, however, is less standardized. In France, patients who are scanned for diagnostic purposes automatically receive a copy of the scans on a disc, whereas in Canada a copy needs to be requested each time and there may be a fee associated with the provision of the copy.
There are many examples of artists who have worked with their own medical scan data, which was originally produced for diagnostic purposes and then acquired by them to create artworks. British film maker Victoria Mapplebeck used her own medical scans as part of her VR film Waiting Room. Mapplebeck (2019) writes that she used “CT scans, mammograms and ultrasound to provide a 3D portrait of my body from the inside, out” as a way to tell the story of her breast cancer experience from its diagnosis through its treatment and to her recovery. Waiting Room VR layers and combines mobile phone footage, head-mounted GoPro footage, precisely placed voice recordings and CGI models to make the viewer feel they are a fly on the wall at every stage of Mapplebeck’s breast cancer experience (British Broadcasting Corporation 2019b). The inclusion of the scan data in the Waiting Room alongside film footage adds another layer of intimacy to her work, literally inviting the viewer into Mapplebeck’s body and to see her cancer.
There are also cases of artists working with medical researchers specifically to create artworks. British artist Jane Prophet, for example, in 2014 worked with neuroscientists Zoran Josipovic from NYU and Joshua Skewes from Aarhus University to create Neuro Memento Mori, a sculpture and video mapped projection generated from functional MRI data (scans that record brain activity) acquired as Prophet was looking at representations of memento mori and vanitas paintings as well as meditating/contemplating death (Prophet 2014). In her February 28, 2016, blog post where she reflects on the experience of being scanned for the Memento Mori project, Prophet writes about her anxiety before the scan of being able to hold still for the duration of the scan, explaining that she had always been a “fidget,” even as a child.
When I was told I had to be very still for a series of seven minute MRI scans I was worried. I was a kid who, when bad dreams sent me running to my parents’ bedroom, kept my mum awake all night as I kicked and wriggled while “peacefully” asleep. That’s the kid that grew into a woman who nightly and tosses and turns. How could I possibly stay still in the scanner? Let along [sic] REALLY still. Not even swallowing…Ironically, given the experiments we performed, I needed to still my body, to “play dead” in order to prevent micro movements. (Prophet 2016)

Jane Prophet, Neuro Memento Mori, 2014, 3D printed sculpture with projection mapping.
Image courtesy of the artist.
French artist Marc Didou uses both the data acquired and the experience of being scanned to create large steel, marble sculptures. For Didou, it is crucial that he is the scanned subject because the experience allows him to see and feel something entirely new. In an interview with Silvia Cassini, Didou explains that “an MRI scan is for me like a vibration-drawing, transparent and monochrome, that neither my hand or eye could have observed or drawn” (Casini 2009).

Marc Didou, Gisant, 2007–2010, steel and acrylic, 105 x 192 x 71 cm. Image courtesy of the artist.
In 2018, working with researchers Kumar Punithakumar, Richard Thompson and Peter Seres at the University of Alberta, Marilène Oliver and Gary James Joynes created the VR artwork, Deep Connection, using full body 3D and 4D MRI scan data of Oliver’s own body. When the viewer enters Deep Connection, they see her scanned body lying prone in mid-air. The viewer can walk around her scanned body and inspect it, lie underneath, and walk through it. The user can dive inside and see its inner workings, its lungs, spine, brain. The user can take hold of the figure’s outstretched hand: holding the hand triggers a 4D dataset, making the heart beat and lungs breathe. When the user lets go of the hand, the heart stops beating and the lungs stop breathing. Deep Connection creates a scenario where an embodied human becomes the companion for a virtual body and where the physical body interfaces with the virtual to animate it. When the VR artwork is exhibited, it is done so as part of an installation that includes sculptures generated from the scan data that has the VR hardware embedded in it. Whenever possible, Oliver is present in the exhibition so that she is able to guide the viewer through the experience. The concept here is that the viewer interfaces with Oliver as a virtual object (the rendered dataset, a physical digital copy and the original).

Darian Goldin Stahl, The Importance of Dualism 2014, photo intaglio and encaustics, 23 x 25cm.
Image courtesy of the artist.
American artist Darian Goldin Stahl works with scans of her sister, Devan Stahl, a professor of medical ethics who has multiple sclerosis. Since 2015, Stahl has incorporated her sister’s scans in her printed works. She has created several beautiful and tender artist books that combine and layer the MR scans with text from Devan’s diaries that “tell her [sister’s] diagnostic narrative and convey how it felt to see her MRI scans for the first time” (Stahl 2014). Darian explains that the pages of the her book, The Importance of Dualism, echo the slicing her sister’s anatomy by the MRI scanner and that the binding of the The Importance of Dualism “alludes to the tension she feels with her body” (Stahl 2014).
Marilène Oliver’s first work made with medical scan data was Family Portrait, a sculptural installation for which she arranged to have each of her family members MRI scanned at 20mm axial intervals at the Nottingham Queen’s Medical Centre, UK. Later, Oliver screen printed the scans onto sheets of clear acrylic and stacked them to create a row of life-size sculptures. In Family Portrait, her father, mother, sister and Oliver herself are presented as elusive hovering figures, suspended in shiny, rigid structures. The spaces between the sheets mean that at eye level the viewer sees straight through the stacks of printed acrylic. With Family Portrait, Oliver was interested to understand and expose the digital and mechanical processes involved in MRI, as well as address posthumanist notions of digital preservation and a fear for the loss of embodied human interactions as a result of digitally mediated communication.
As more and more data is generated and collected from and about individuals, there is the question of what will happen to this data when we die. As Professor Remigius Nwabueze (2021) detailed in his keynote presentation at the KTVR e-Symposium, there is little legislation protecting the privacy of the dead. There is increasing discussion in the media and scholarship about digital legacies and writing digital wills (Bakewell 2017; TalkDeath 2019; Kasket 2020). Should medical scans be included in a digital will? What might it mean to inherit medical scans and other kinds of personal data from a deceased loved one? How are datasets or social media accounts different from photographs and letters?
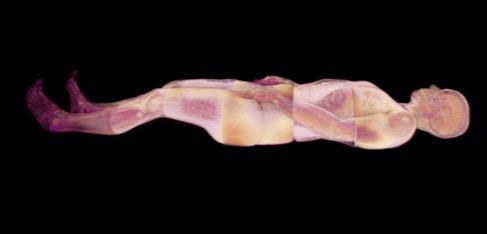
Marilène Oliver and Gary James Joynes, 2019. Screen capture of Deep Connection, VR artwork.
Image courtesy of the artists.

Marilène Oliver, Family Portrait 2003, screen prints on acrylic, each sculpture 50 x 70 x 192 cm.
Open-source datasets
In many cases and especially in the exploratory stages of a project, it may not be necessary or relevant to work with personal scans/data. The acquisition of new data is a complex, lengthy, expensive process that requires access to research collaborators and institutions. It also requires a lot of energy to run the large and complex machines such as MRI and CT scanners. Furthermore, it takes time away from medical research. At the end of this section there is a list of open-access scan data repositories from around the world. These are almost all free to use for “research purposes.” Most databases and repositories will include information about the study for which the data was originally acquired. The OpenNeuro database, for example, is an open-access repository of scan datasets that researchers have uploaded for other researchers to use. Researchers who upload data to OpenNeuro have agreed that they have ethics permissions to share the data publicly, that the data has been de-identified and defaced (using pydeface), and that it is publicly available under a Creative Commons license. Each dataset has its own digital object identifier (DOI), making it easily traceable to the original study. Each dataset has its own README file with information about the original study, which typically includes demographic information such as when the data was acquired, how many subjects were scanned, and what other data was collected as part of the study. Often, the title of the dataset will also give explanatory information about why it was acquired.
For example, the dataset titled “Emotion Regulation in the Ageing Brain, University of Reading” (Lloyd et al. 2021), accessible on the OpenNeuro platform, quickly indicates the original reason for acquiring the data, and suggests the scan subjects will be older and that there will be comparative functional scans that compare different emotions. It would be important in this case to read published papers related to the study to understand what the data represents. It is understandable that the original researcher and data subjects would object to an “incorrect” use of the data (such as if the aforementioned datasets where used as a part of an artwork about children’s emotions). This is a good example of when it would be wise to reach out to the original researchers both to confirm they are agreeable to the data being used for creative research and to invite a conversation about the data and its findings. It is so easy to download data, but someone somewhere worked hard to create it and will probably be very happy to hear from another researcher or artist who is interested in working with the data in a surprising and experimental way.
Other data repositories, such as Open Access Series of Imaging Studies (OASIS), are available through institutions via an application process, which often includes an ethics review of the proposed work and may include restrictions on how the data can be used. The American National Institute of Mental Health’s brain mapping project, the Human Connectome Project, also has a huge repository of brain datasets. Accessing the repository requires the completion and approval of a time-limited Data Use Certificate (DUC) (National Institute of Mental Health 2021). The DUC terms and conditions include clauses such non-transferability of the data, research-only use, no redistribution, deletion of data after the study has ended, and agreeing to share publications of “other public disclosure” with the NIMH. It also includes a useful clause (no. 5) that there will be no attempted re-identification of subjects or their relatives, and that in the case that “identifying information is discovered,” users will notify the NIMH (2021).
In addition to open-access research datasets collected and made available by research institutions, radiology software often comes with libraries of datasets. The software OsiriX-Viewer, for example, which is available via subscription, comes with an image library of high-resolution scan datasets. OsiriX-Viewer stipulates that the datasets are for research and teaching only and cannot be redistributed, sold, or used for commercial purposes. Another open-source research software platform, 3D Slicer also provides scan datasets to be used with the software. A wiki page about the “Sample Data” invites new data to be added to the Sample Data module of the software. There is no restriction on the use of 3D Slicer or the datasets, but the developers make clear that it is the user’s responsibility to ensure compliance with any applicable rules and regulations: “Slicer is NOT approved for clinical use and the distributed application is intended for research use. Permissions and compliance with applicable rules are the responsibility of the user” (3D Slicer 2020).
Through making several artworks with scan data over more than two decades, Marilène Oliver has found that most researchers and institutions respond to requests to use data to explain either why it isn’t possible to share the data, or the conditions under which it can be used. Indeed, connecting with researchers with requests to use scan data has led to both a positive exchange of ideas and a broadening of audience. Since 2007, Oliver has made numerous artworks using one of the datasets available in the OsiriX-Viewer Image Library called Melanix. When she first started working with Melanix, Oliver contacted the creators of OsiriX-Viewer to tell them about her creative work with Melanix and to confirm that her creative use didn’t contravene their data permissions. This contact later led to both an exhibition of her works in the Geneva University Hospital gallery, where the software was developed, and the inclusion of her works in Le corps et son image, a book by one of the key developers of OsiriX-Viewer (Ratib 2011). Likewise, Oliver’s request to work with the CT scans of the infamous mummy Otzi the Iceman led to the sculpture she created with the scans, Iceman: Frozen, Scanned and Plotted, being exhibited at the Südtiroler Archäologiemuseum in Italy in 2011.
Key Datasets
In the KTVR research project, a number of scan datasets have been particularly helpful to think about the ethical use of secondary data—notably, the Visible Human Project, Ben Body, and BrainWeb.
The Visible Human Project
In 1994 the National Library of Medicine released the Visible Human, a dataset that includes CT, MRI, and cryosections of a male cadaver. Until 2019 a license was required to work with the data, but it is now publicly available with no permissions. The male cadaver was Joseph Paul Jernigan, a Texan convicted murderer who was killed by lethal injection in 1993. Before he was executed, he was reportedly convinced by the prison chaplain to donate his body to medical science. Despite only having one testicle and a missing tooth, Jernigan was selected from thousands of possible specimens to become the Visible Human (Waldby 2000). The Visible Human is still one the few full body scan datasets available and has been used by thousands of research teams. The Visible Human has also
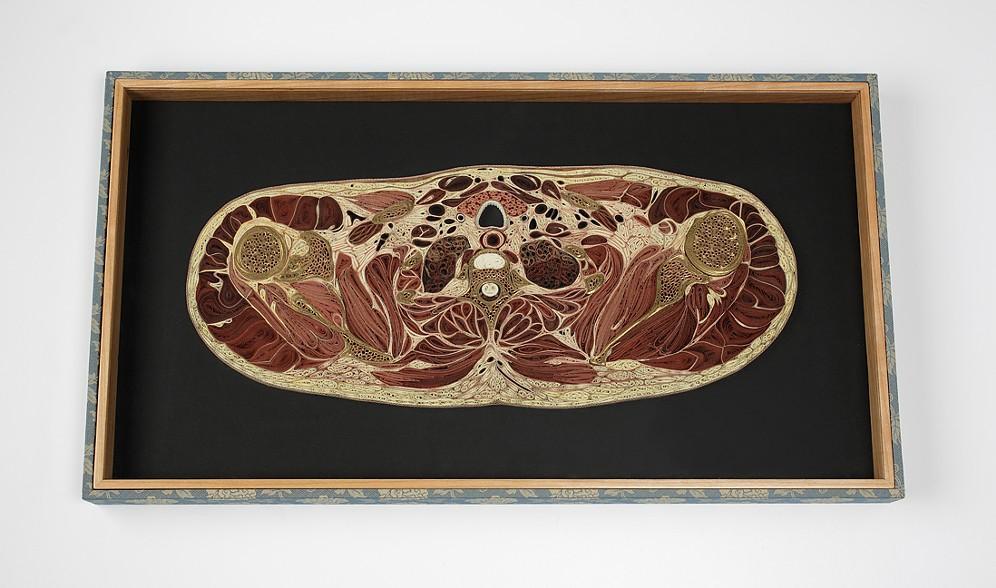
Lisa Nilsson, Shoulders 2013, mulberry paper, 58 x 32 x 4 cm.
Image courtesy of the artist.
been written about in countless newspapers articles, and has been the subject of several documentaries and books. It has also been used by numerous artists to create artworks. Lisa Nilsson, for instance, has worked extensively with the VHP dataset to create complex and captivating quilled (rolled and shaped paper) works. Likewise, Miltos Manetas and Aaron Russ Clinger’s web-based work Man in the Dark (Moss 2009) transformed the VHP images into a poetic floating body that dangles from the cursor.
The Visible Human is now part of a larger Visible Human Project (VHP) which has grown to include multiple datasets from different subjects. A later VHP dataset created from the body of Susan Potter, is quite a different case from Jernigan. After learning of the early Visible Human Projects, Potter, who was a cancer survivor and disability rights activist, convinced Dr. Victor Spitzer, the lead VHP researcher, to make her into a “visible human” when she died (Becoming Immortal 2018). At first, Spitzer resisted because the VHP was meant only to focus on digitizing healthy, “normal” bodies. Fifteen years passed between the time Spitzer agreed that Potter would be the next VHP subject and when she died in 2015. Over that time, they worked closely together and became friends. A National Geographic documentary made about their relationship shows how Potter was committed to making sure that “abnormal” bodies were also digitized for the purposes of medical education. When Potter first approached Spitzer, she had had twenty-six surgeries related to a car accident and was later diagnosed with melanoma, breast cancer, and diabetes. Spitzer insisted on digitizing Potter’s life as well as her death by gathering her personal experiences and thoughts about her body, including her descriptions of her pain and her desire to donate her body to medical science. The Susan Potter VHP dataset is the most fully digitized human body, extending to these video and audio recordings. Yet the Visible Human Female dataset, available for free download on the National Library of Medicine website, is not that of Susan Potter but of a “Maryland Housewife” whose body was explicitly donated to the VHP by her husband after she died of a heart attack in 1995 (Waldby 2000, 2). It is not clear why the data that Susan Potter authorized for public release is not yet freely available.
Paywall datasets that have been expertly segmented and cleaned
Echoing the history of anatomy where beautifully illustrated hand-printed anatomical encyclopedias sold for a high price, there are also commercially available high-resolution datasets that include organs, the lymphatic, vascular, and nervous systems expertly mapped into them. Ben Body, by the Swedish company Interspectral in collaboration with Benjamin Moreno, is an “exhibition” based on a full body CT scan that can be rented by museums or institutions and explored via a touchscreen table. Renting the exhibition has a high price tag of €3,000, but given that the data took over a year to segment, this is a model of data usage that recognizes the work and expense of acquiring and processing data. The full Interspectral catalogue (Interspectral 2020) advertises a virtual ark of datasets for sale, including a scan of a woman who died in a traffic accident, a stroke patient, a full body scan of a man in his fifties in good health whose scan demonstrates aging, a chimpanzee, a golden eagle, a grey seal, a lion, a moose, several sharks, two stingrays, a fly, a beetle, a spider, and an ant.
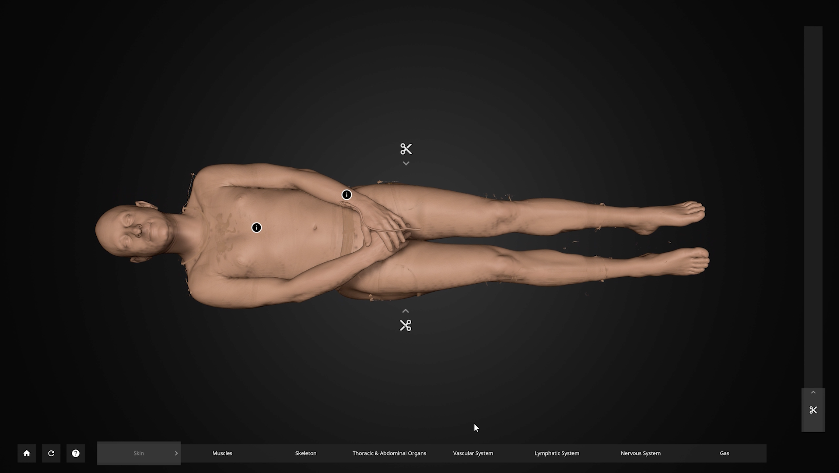
Screenshot of Ben Body exhibition, 2022.
Simulated and Synthetic Data
Already in the late 1990s, researchers at McGill University had created datasets of a simulated, phantom brain. The project, called BrainWeb, includes both a “normal brain” and an “MS brain” (Montreal Neurological Institute and McConnell Brain Imaging Centre, n.d.). These datasets were created by averaging multiple datasets to create a single standardized set of scans that other scans can be registered or aligned to (Collins et al. 1998). It is important in medical research when comparing multiple brain scans first to ensure they are all orientated in the same way as this is difficult to ensure when the subject is scanned. It would be important when using the BrainWeb datasets as creative researchers to be thoughtful about working with an averaged MS brain rather than the averaged “normal” brain and vice versa—not only because mis-using a dataset would no doubt invite objection by the researchers, but because it would be disrespectful to the original data subjects whose data contributed to the creation of the BrainWeb datasets.
Machine learning is also being used to generate high-resolution synthetic datasets. Researchers are working with generative adversarial networks (GANs) trained on large datasets of real scans to learn patterns and rules within scan datasets from which to generate synthetic or “fake” data (Mirsky 2019). Again, here the original subject of the scan does not exist—the machine learning model is generating new scans based on what it has observed in the dataset of scans it has been fed.
In some cases, synthetic data may be an alternative to conventional data, and, depending on the proposed use, synthetic data could provide a dataset relatively free of privacy issues. According to a 2020 Benaim et al.) study, when based on a large enough population, synthetic data resulted in similar findings to conventional data. Because the data subjects in synthetic data do not exist, there is no possibility of disclosure. Depending on the type of data used, it may still be important to consider who the dataset was modelled on, including the make-up and size of the sample population.
While this emerging area promises to alleviate certain privacy issues, it is not without its own challenges. Decisions made in the construction of the dataset can introduce bias into the results, and the value of the data itself can be compromised if the underlying dataset is processed multiple times. How much “reality” is left and does that matter? Or could be a conceptual element of the work that the data visualized is an aggregation of thousands of bodies or brains? Media artist Refik Anadol’s 2021 work Sense of Space was created from synthetic data generated from the Human Connectome Project (HCP), which is built from 70 terabytes of multimodal MRI scans from over 4,500 subjects (Anadol and Hotamisligil 2021). The project, which was made in collaboration with the coordinator of the HCP, Dr. Taylor Kuhn, presents the architecture of the brain as an immersive experience into which the viewer can enter. In Sense of Space, the fact that the brain space that viewers enter is generated from thousands of brains “from birth to nonagenarians” is conceptually central to the work, speaking to the 2021 Venice Architecture Biennale’s theme “how will we live together?.” Anadol and his collaborators present a utopian, technologically enabled, corporately sponsored (Siemens, NVIDIA, Epson, Arup, AiBuild) architectural structure that is an “every brain.” The HCP’s massive database includes scans of healthy brains from subjects of various ages, as well as brain scans acquired as part of studies for epilepsy, anxiety and depression, aging and dementia, early psychosis, and anxious misery. Only “healthy brains,” however, are used for Sense of Space (Anadol and Hotamisligil 2021), most likely because of the complexity of amalgamating so many datasets and the scientific need to control the data when making the connectome model. From an artistic perspective, however, excluding neuro diverse datasets when making an artwork that proposes a future way of ‘living together’ is important to be conscious of and carefully considered.

Refik Anadal, Sense of Space 2021, AI projection mapping and 3D printing.
Image courtesy of the artist.
Missing datasets
Despite the abundance of data that exists, there are times when data for a particular situation does not exist. Since data is collected for a purpose, a lack of data can speak to power imbalances about who is determining what data should be collected. Dataset acquisition is expensive, and most research occurs in economically and technologically developed parts of the world, reflecting the social and economic disparities in access to health care both within a given society and across the globe. If diverse populations are not accessing health care equally, there will be less data (scans, etc.) from those populations. Considering medical datasets and AI, there is a good deal of literature examining how homogenous (usually white) datasets have caused significant problems when applied to a diverse population. Certain groups, such as older minority communities, can be systematically excluded from medical research, resulting in institutional bias or racism (Bécares, Kapadia, and Nazroo 2020). Women have also historically been underrepresented in clinical research (Criado-Perez 2019). Mimi Ọnụọha is an artist whose work highlights the social relationships and power dynamics behind data collection. In her bright white installation The Library of Missing Datasets (2016), Ọnụọha presented a filing cabinet full of empty files representing uncollected data as “things that have been excluded.” Each empty file is labelled to identify the missing data. Examples of empty files in the cabinet include people excluded from public housing because of criminal records, public lists of citizens undergoing domestic surveillance, white children adopted by People of Colour, and the quantifiable effect of corruption in lean economies. Ọnụọha added another volume to the work in 2018, which focuses on Blackness. As well as the physical installation, there is also a Github repository for the project, which is empty save a README file explaining the project and an essay about information networks and power dynamics (Ọnụọha 2016b; Bossewitch and Sinnreich 2013).

Mimi Ọnụọha, The Library of Missing Datasets 2016, mixed-media installation.
Image courtesy of the artist.
Provenance, Access, and Licencing Discussion Questions
• Who are the data subjects? Is there demographic information about who is in the dataset? (This could be data within the dataset or it could be a generalized summary of the data subjects.) From what geographical location were the participants recruited?
• How were the data participants recruited? Was it an open call to the public? Was a particular group of people targeted (e.g., students, employees of an institution, etc.)? Does the method of recruitment affect the artwork that uses the data?
• For older datasets or for datasets where the donors are known to be deceased, is the consent that was given while alive appropriate in order to respect the privacy for the dead or their families? Does using the data impact those who knew the data subjects when they were alive?
• Is there a Creative Commons license for the data? If so, what kind?
• Should you contact the original creator of the data to find out more about the original study and confirm permission for creative research?
Synthetic Data Discussion Questions
• Does the work examine issues related to a specific community or group of people? Does the synthetic data accurately reflect that group? Does a dataset exist that can be used without compromising the wishes or the privacy of the data subjects?
• Does the work depend on the lived experiences of individuals captured in the data, or will the data be used in a much more general, non-specific way? Does synthetic data exist that can be used instead?
List of selected open-access medical image repositories
Alzheimer’s Disease Neuroimaging Initiative
http://adni.loni.usc.edu/data-samples/access-data/
Cancer Imaging Archive
https://www.cancerimagingarchive.net/collections/
Embodi3D
Interspectral
MedPix
https://medpix.nlm.nih.gov/home
OpenNeuro
Oasis
OsiriX
https://www.osirix-viewer.com/resources/dicom-image-library/
Further links
https://www.aylward.org/notes/open-access-medical-image-repositories
https://radrounds.com/radiology-news/list-of-open-access-medical-imaging-datasets/